CaptionSmiths: Flexibly Controlling Language Pattern in Image Captioning
ICCV2025'%3e%3cmetadata%20id='metadata16'%3e%3crdf:RDF%3e%3ccc:Work%20rdf:about=''%3e%3cdc:format%3eimage/svg+xml%3c/dc:format%3e%3cdc:type%20rdf:resource='http://purl.org/dc/dcmitype/StillImage'%20/%3e%3cdc:title%3e%3c/dc:title%3e%3c/cc:Work%3e%3c/rdf:RDF%3e%3c/metadata%3e%3cdefs%20id='defs14'%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath28'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path26'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath128'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path126'%20/%3e%3c/clipPath%3e%3cclipPath%20clipPathUnits='userSpaceOnUse'%20id='clipPath18'%3e%3cpath%20d='M%200,1080%20H%201920%20V%200%20H%200%20Z'%20id='path16'%20/%3e%3c/clipPath%3e%3c/defs%3e%3csodipodi:namedview%20pagecolor='%23ffffff'%20bordercolor='%23666666'%20borderopacity='1'%20objecttolerance='10'%20gridtolerance='10'%20guidetolerance='10'%20inkscape:pageopacity='0'%20inkscape:pageshadow='2'%20inkscape:window-width='1440'%20inkscape:window-height='914'%20id='namedview12'%20showgrid='false'%20fit-margin-top='0'%20fit-margin-left='0'%20fit-margin-right='0'%20fit-margin-bottom='0'%20inkscape:zoom='0.434375'%20inkscape:cx='484.54599'%20inkscape:cy='90.825431'%20inkscape:window-x='-6'%20inkscape:window-y='-6'%20inkscape:window-maximized='1'%20inkscape:current-layer='g18'%20/%3e%3cg%20id='g18'%20inkscape:groupmode='layer'%20inkscape:label='SINICX_Logo_2024_06%20(1)'%20transform='matrix(1.3333333,0,0,-1.3333333,-871.99998,786.66665)'%3e%3cg%20id='g122'%3e%3cg%20id='g124'%20clip-path='url(%23clipPath128)'%3e%3cg%20id='g130'%20transform='translate(1236,540)'%3e%3cpath%20d='m%200,0%20c%200,14.984%209.494,26.752%2030,27.5%20l%20-2,20%20C%20-3,45.572%20-22,25%20-22,0%20c%200,-25%2019,-45.572%2050,-47.5%20l%202,20%20C%209.494,-26.752%200,-14.984%200,0%20m%20-74,47.5%20-2,-20%20c%2020.506,-0.748%2030,-12.516%2030,-27.5%200,-14.984%20-9.494,-26.752%20-30,-27.5%20l%202,-20%20c%2031,1.928%2050,22.5%2050,47.5%200,25%20-19,45.572%20-50,47.5%20M%20-158,-50%20c%2010.163,0%2023.222,1.516%2035.5,7.5%20l%201,21.5%20c%20-15.419,-7.98%20-24.349,-9.5%20-34,-9.5%20-22.885,0%20-35,10.715%20-35,30.5%200,20.281%2011.498,31%2033.5,31%2010.539,0%2019.19,-2.25%2033.5,-10%20l%20-1,21%20c%20-12.951,6.497%20-23.605,8%20-33.5,8%20-34.125,0%20-55.5,-19.341%20-55.5,-50%200,-30.784%2021.128,-50%2055.5,-50%20m%20-103.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20M%20-536,-50%20c%2027.127,0%2042,11.809%2042,30.326%200,23.018%20-24.358,28.393%20-43.5,31.7%20-13.347,2.306%20-23,4.28%20-23,10.8%200,5.697%206.895,8.092%2021.673,8.092%2013.023,0%2027.965,-2.697%2040.327,-7.592%20l%20-1,21%20C%20-515.737,49.045%20-526.907,50%20-539,50%20c%20-26.578,0%20-43,-10.415%20-43,-27.122%200,-22.856%2023.488,-27.807%2042.038,-31.027%2013.246,-2.343%2024.462,-4.36%2024.462,-12.006%200,-8.118%20-10.957,-10.019%20-20.5,-10.019%20-15.487,0%20-27.243,4.543%20-45.5,13.674%20l%201,-22.5%20c%2015.24,-7.948%2031.788,-11%2044.5,-11%20m%2077.5,2.5%20h%2022%20v%2095%20h%20-22%20z%20m%2060.5,95%20h%2021%20l%2055,-63.5%20v%2063.5%20h%2022%20v%20-95%20h%20-21%20L%20-376,16%20v%20-63.5%20h%20-22%20z'%20style='fill:%23000000;fill-opacity:1;fill-rule:nonzero;stroke:none'%20id='path132'%20/%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Overview
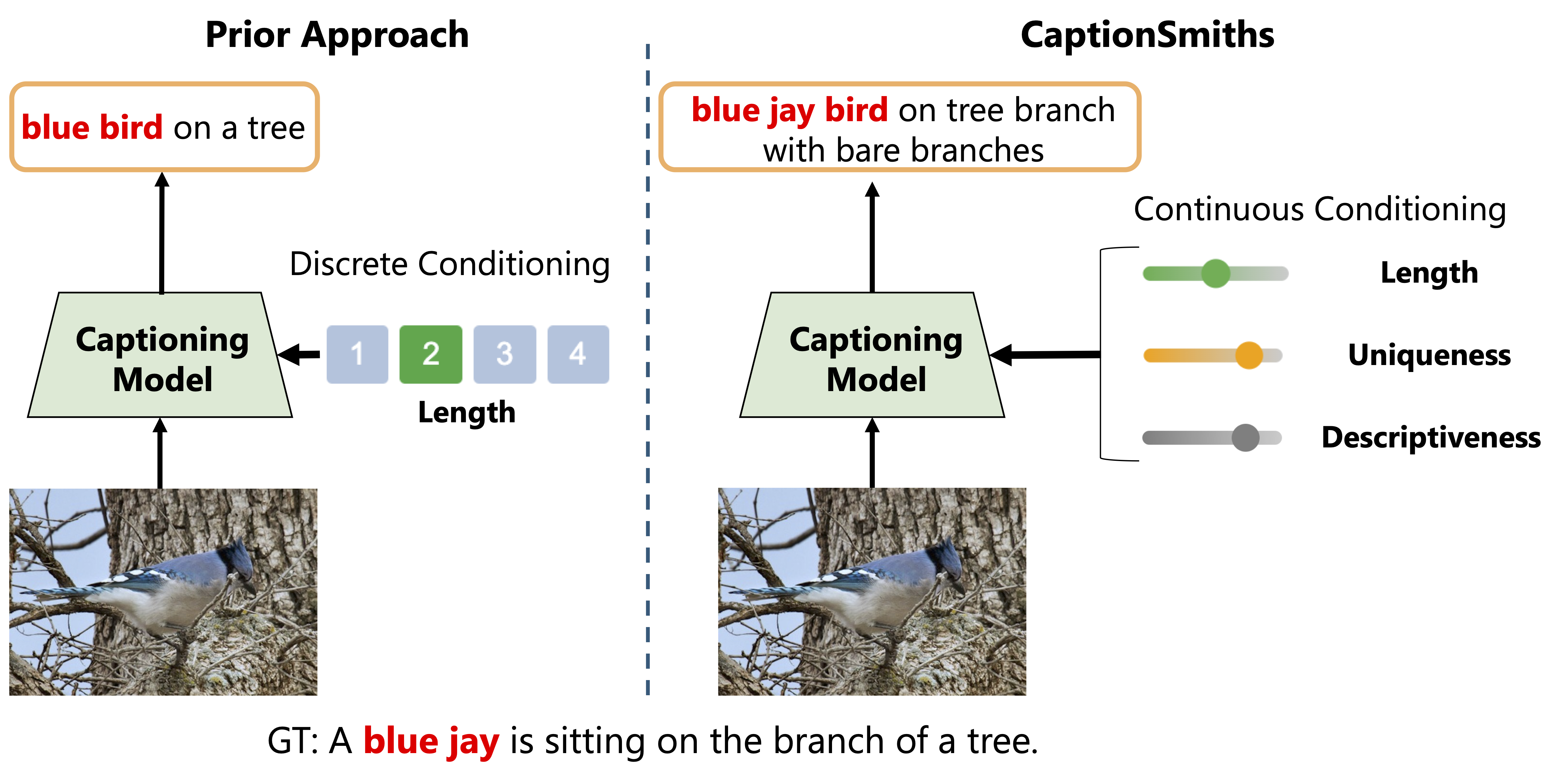
CaptionSmiths is a controllable image captioning framework that allows smooth adjustment of caption properties such as length, descriptiveness, and word uniqueness—within a single model. Unlike existing models, which lack explicit conditioning and struggle with smooth transitions between styles, CaptionSmiths quantifies these properties as continuous scalar values and interpolates between learned endpoint representations (e.g., very short ↔ very long). This enables fine-grained control over caption styles. Experiments show that CaptionSmiths not only improves lexical alignment, but also reduces caption length control error by over 500% compared to strong baselines.
CaptionSmiths
Method
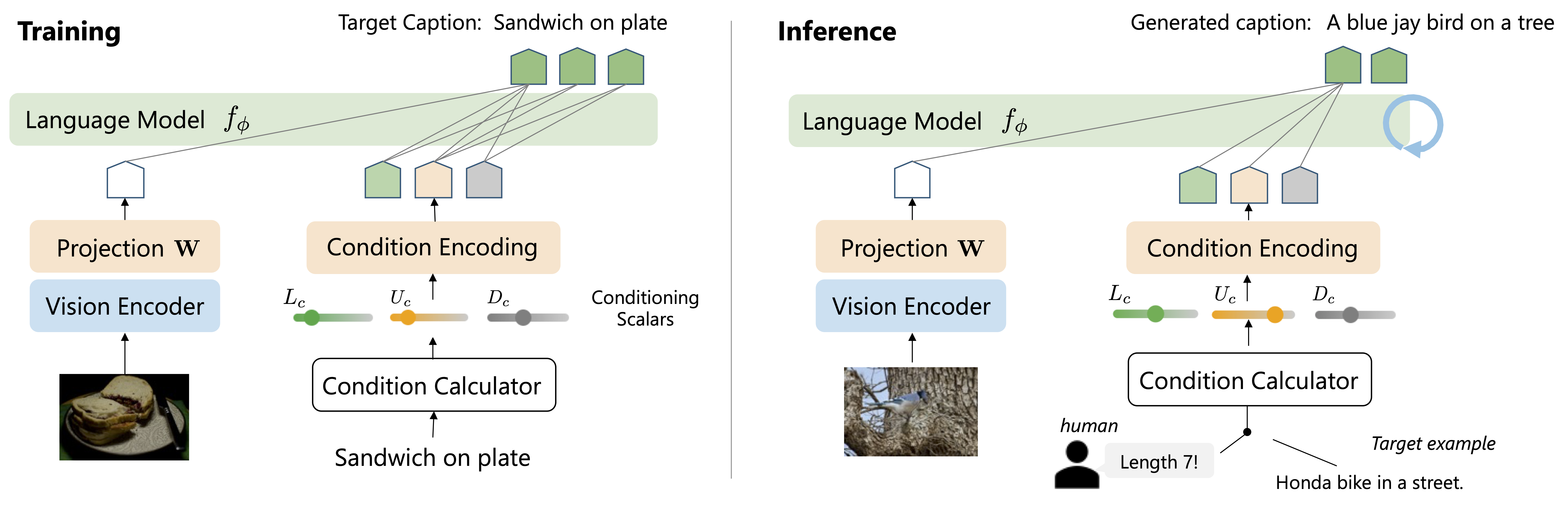 Overview during training (left) and inference (right). Left: We compute conditioning values for each caption in Condition Calculator. The conditions are converted into token embeddings via Condition Encoding. Then, the learnable parameters are trained to control the language pattern in the output caption. Right : In inference, users can either manually specify the conditioning scalars or employ an example language pattern as a sentence. Here's our demo text showcasing the power of markdown and KaTeX integration! Markdown allows you to easily format text using simple syntax.
Overview during training (left) and inference (right). Left: We compute conditioning values for each caption in Condition Calculator. The conditions are converted into token embeddings via Condition Encoding. Then, the learnable parameters are trained to control the language pattern in the output caption. Right : In inference, users can either manually specify the conditioning scalars or employ an example language pattern as a sentence. Here's our demo text showcasing the power of markdown and KaTeX integration! Markdown allows you to easily format text using simple syntax.
Results
Evaluating descriptiveness control
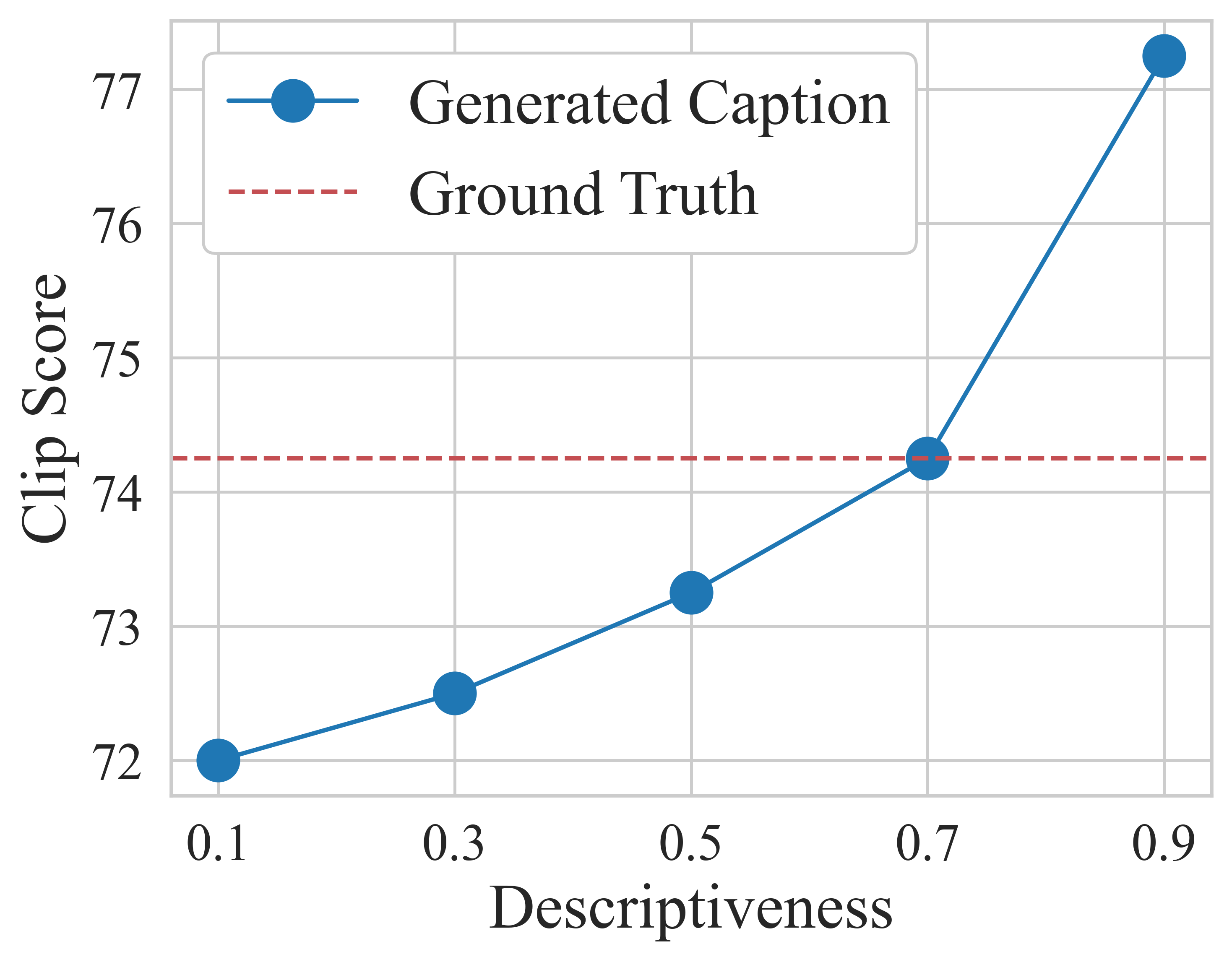
Figure: Increasing the input value corresponding to descriptiveness improves CLIPScore.

Figure: Results of varying descriptiveness score in caption generation.
The graph above shows the qualittive results of controlling descriptiveness of captions. Increasing the value improves the CLIPScore. The figure shows the examples of generated captions in varying the descriptiveness condition. Increasing the value tends to output more descriptive captions.
Evaluating uniqueness control

Figure: Results of varying descriptiveness score in caption generation.
CaptionSmiths also controls the uniqueness in the vocabulary of output captions. The example above shows the results of outputting fine-grained words to describe entities in images.
Evaluation on lexical alignment
| Models | Parameter Size | MSCOCO (Short) | LN COCO (Middle) | Docci (Long) |
|---|---|---|---|---|
| LLaVA-1.5 | 7.1B | 0.0 | 1.1 | 2.4 |
| Blip-3 | 4.6B | 57.5 | 2.0 | 3.6 |
| Qwen2-VL-7B | 8.3B | 84.3 | 3.8 | 5.5 |
| Vanilla Supervised | 21.3B | 96.6 | 23.6 | 1.4 |
| Fine-tuned LLaVA-1.5 | 21.3B | 98.3 | 23.9 | 9.1 |
| Vanilla | 7.1B | 13.2 | 21.7 | 7.5 |
| Concap | 7.1B | 95.9 | 23.5 | 8.3 |
| CaptionSmiths | 7.1B | 104.8 | 37.4 | 29.7 |
Contact
Citation
# arXiv version