Learning to Detect Every Thing in an Open World
Kuniaki Saito1 Ping Hu1 Trevor Darrell2 Kate Saenko1, 3
1. Boston University 2. University of California, Berkeley 3. MIT-IBM Watson AI Lab
Paper | Code | Another Demo Video
Abstract
Many open-world applications require the detection of novel objects, yet state-of-the-art object detection and instance segmentation networks do not excel at this task. The key issue lies in their assumption that regions without any annotations should be suppressed as negatives, which teaches the model to treat the unannotated objects as background. To address this issue, we propose a simple yet surprisingly powerful data augmentation and training scheme we call Learning to Detect Every Thing (LDET). To avoid suppressing hidden objects (background objects that are visible but unlabeled), we paste annotated objects on a background image sampled from a small region of the original image. Since training solely on such synthetically-augmented images suffers from domain shift, we decouple the training into two parts: 1) training the region classification and regression head on augmented images, and 2)~training the mask heads on original images. In this way, a model does not learn to classify hidden objects as background while generalizing well to real images. LDET leads to significant improvements on many datasets in the open-world instance segmentation task, outperforming baselines on cross-category generalization on COCO, as well as cross-dataset evaluation on UVO and Cityscapes.

Paper
arxiv, 2021.
Citation
Kuniaki Saito, Ping Hu, Trevor Darrell, Kate Saenko.
"Learning to Detect Every Thing in an Open World
".
Bibtex
Open World Instance Segmentation
State-of-the-art object detectors are designed to detect objects, which are given annotations in dataset, while they do not excel at detecting novel objects. However, many applications require to localize objects though it may not be necessary to identify their categories. In the open world instance segmentation, the model needs to localize novel objects in the scene.
Challenge in Open World Instance Segmentation

What limits the ability of detectors to locate novel objects? First, most datasets do not annotate all objects in a scene. The above is the images from COCO. The colored boxes are annotated while other regions are not. Note that there are many unlabeled objects (marked with white dashed boxes) in the scene. Then, the detectors are trained to suppress the unlabeled objects as "background". This discourages the detectors to detect novel objects.
Data Augmentation: Background Erasing
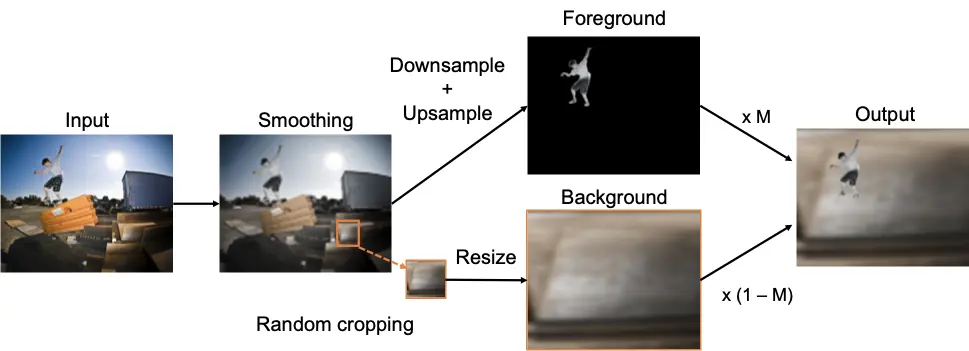
First, to avoid suppressing unlabeled objects as background, we propose to erase them by using the mask of foreground objects. We paste foreground objects on a background image and train a detector on the synthesized image. Since we need a background image, which does not contain foreground objects, we propose to create it by cropping a patch from a small region of the input image. But, the synthesized images look totally different from real images, which makes the trained detector work poor on real images.
Decoupled Training
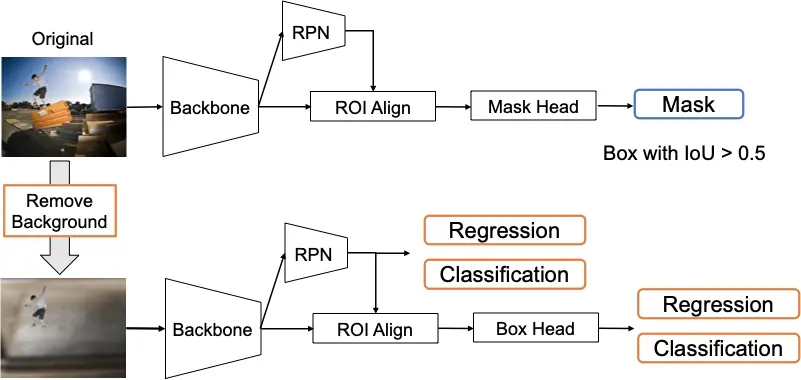
To handle the domain-shift between synthesized and real images, we propose to decouple the training into two parts: 1) training detector losses on synthesized images, 2) training mask loss on real images. In this way, the detector will not suppress unlabeled objects as background while it will generalize well to real images thanks to the mask loss.
Experiments
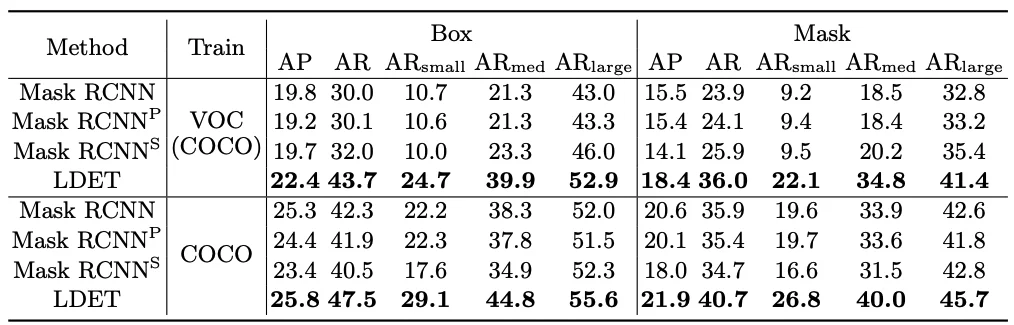
This is the result of models trained on VOC categories of COCO (VOC-COCO) or whole COCO, and tested on UVO. LDET improves on Mask RCNN with a large margin in all metrics. Note that LDET trained on VOC-COCO is comparable to or better than Mask RCNN trained on COCO in AR.
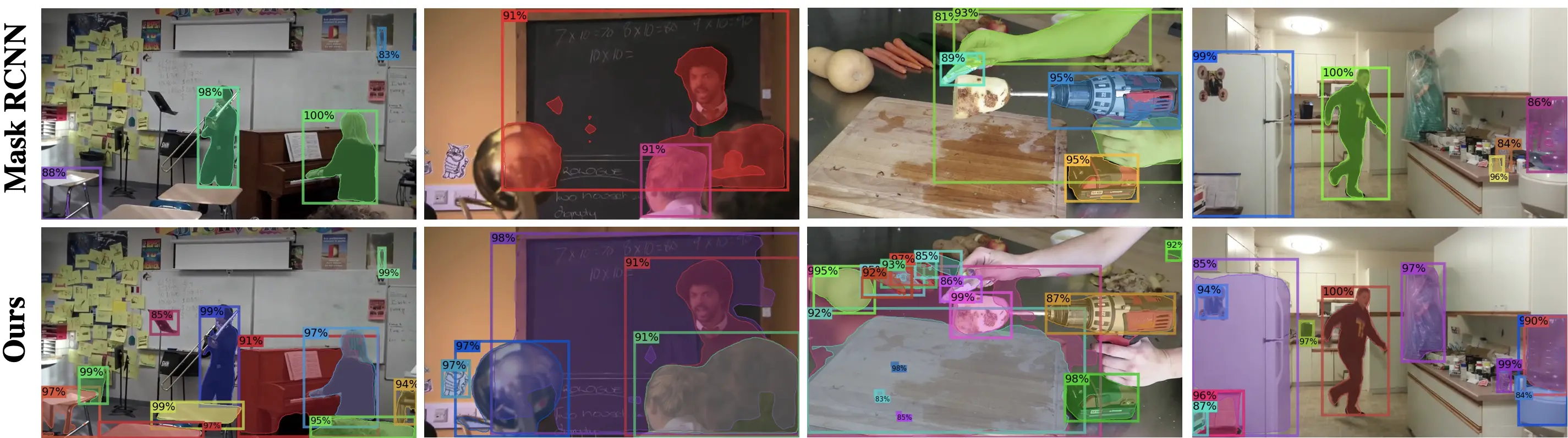
Visualization

Models trained on VOC-COCO are tested on COCO validation images. LDET detects novel objects well e.g., giraffe, trash box, pen, kite, and floats.
Objectness Visualization

Visualization of objectness score from region proposal network. Note that LDET predicts the score well while baseline suppresses the objectness of many objects.